Not really a utility script, but still quite handy…
#!/bin/sh
export PATH=/usr/bin:/usr/sbin
exec /usr/bin/chromium --oauth2-client-id=$GOOGLE_CLIENT_ID_MAIN --oauth2-client-secret=$GOOGLE_CLIENT_SECRET_MAIN $@
Not really a utility script, but still quite handy…
#!/bin/sh
export PATH=/usr/bin:/usr/sbin
exec /usr/bin/chromium --oauth2-client-id=$GOOGLE_CLIENT_ID_MAIN --oauth2-client-secret=$GOOGLE_CLIENT_SECRET_MAIN $@
I’m suffering from failure to comprehend the results here… What does this setup for it to do differently? Just for general knowledge…
Could just type std::string out too  Typically _t is reserved for posix or libc types, eg int8_t or pid_t
Typically _t is reserved for posix or libc types, eg int8_t or pid_t
Not a full script but when I was working on a “random wallpaper selector” I created this unoptimised procedure that will return a random element from a list.
search_path="/usr/share/backgrounds"
wallpaper=$(find ${search_path} -maxdepth 1 -type f | shuf -n1)
echo "${wallpaper}"
The script above will return a name of one file in the given directory.
If you want to specify a list directly in bash script then you can use this.
searchwords=("nature" "animal" "forest" "mountain" "night sky" "space")
searchword=$(echo ${searchwords[$(echo "${!searchwords[@]}" | sed -e "s, ,\n,g" | shuf -n1)]})
echo "${searchword}"
How it works? Basicaly you feed new-line separated list of elements into shuffle which randomly changes order of lines and limit output to the first one -n1. This allows to even have entries with spaces in them.
echo "${!searchwords[@]}"
will list all (because of @) indexes (read numbers) for the given list searchwords (if exclamation mark ! is not there then it return all entries of the list)
sed -e "s, ,\n,g"
will convert all spaces between numbers to new-line characters
shuf -n1
will (if lucky) return 1 random number as a new index which is then used in
echo ${searchwords[RANDOM_NUMBER]}
This will print entry from the list searchwords which has index RANDOM_NUMBER (the previously executed code inside $() block)
Here is a minor optimisation:
Instead of using sed (which is bloat), use tr:
searchword=$(tr ' ' '\n' <<< "${searchwords[*]}" | shuf -n1)
Also, you can use the <<< redirection instead of pipes and echo, and the * wildcard to print the entire array, instead of that $(echo ${searchwords[$(echo "${!searchwords[@]}"... monstrosity.
Hey, I like the monstrosities in my code. ![]()
![]()
But thank you anyway.
Your tr example has a slight problem that entry with spaces in it will be split as well. That is why I had to first convert it to indexes with !.
Good point.
This should work (even faster, as there is no need for tr):
searchword=$(for i in "${searchwords[@]}"; do printf "%s\n" "$i"; done | shuf -n1)
EDIT: actually, that was quite stupid of me, here is a better way to print a random element of an array, without iterating through the entire array, and shuffling it using shuf and outputting printf (so much bloat!), but by utilising the RANDOM variable:
searchword=${searchwords["$[RANDOM % ${#searchwords[@]}]"]}
I am not sure about random-modulo aproach. Some time ago I learned that it is a bad way to do uniform distribution because if 32767 is not exactly divisible by number of “bins” one “bin” will be less likely to be selected.
I have no idea which random engine shuf uses but at least it gives me some comfort in obscurity. 
RANDOM % int is just wrong in principle (insignificantly so in my application but I would know and that is just the worst situation).
I think the benefits outweigh the downsides.
Unless your array contains more than 256 elements (half the number of bits of the maximum random), the distribution will be mostly uniform.
Besides, you don’t need a cryptographically secure RNG to pick a wallpaper. 
Who knows. You haven’t seen my wallpapers. ![]()
What I miss with Kate is Geany’s quick-find box, which finds in the current file, as you type.
Okay, I made a simple Monte Carlo simulation to demonstrate the modulo bias in RANDOM % int RNG.
I wrote the simulation in Bash, so it’s not off topic ![]()
The logic behind it is really simple. It starts with an array where all elements are initialised to 0. Then at random increments the elements, one by one. It repeats this process many times (here, 1000 * size of the array, and in the last sample, 10000 * size) to get definitive probability distributions.
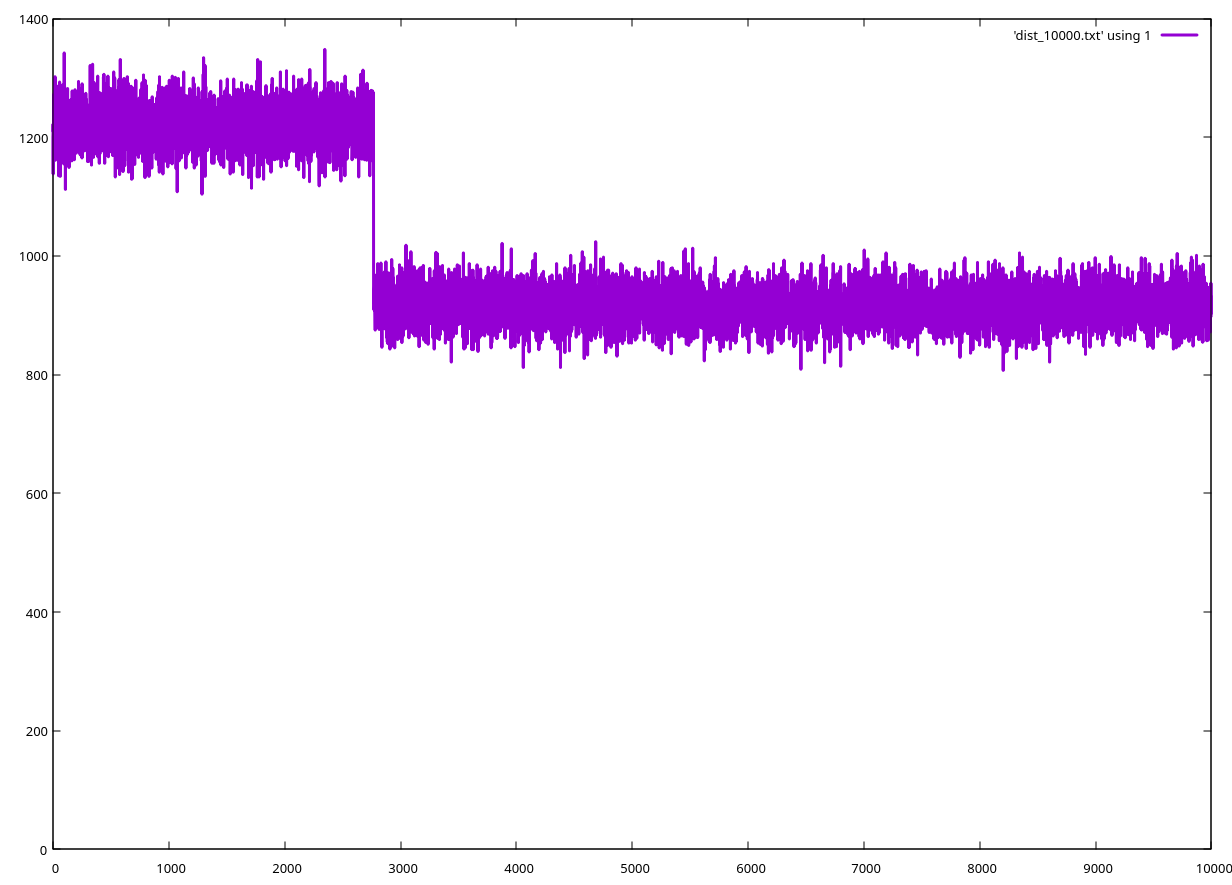
First, for a huge array, consisting of 10000 elements, the bias is obvious, there is a step in the probability distribution after the element 2767:
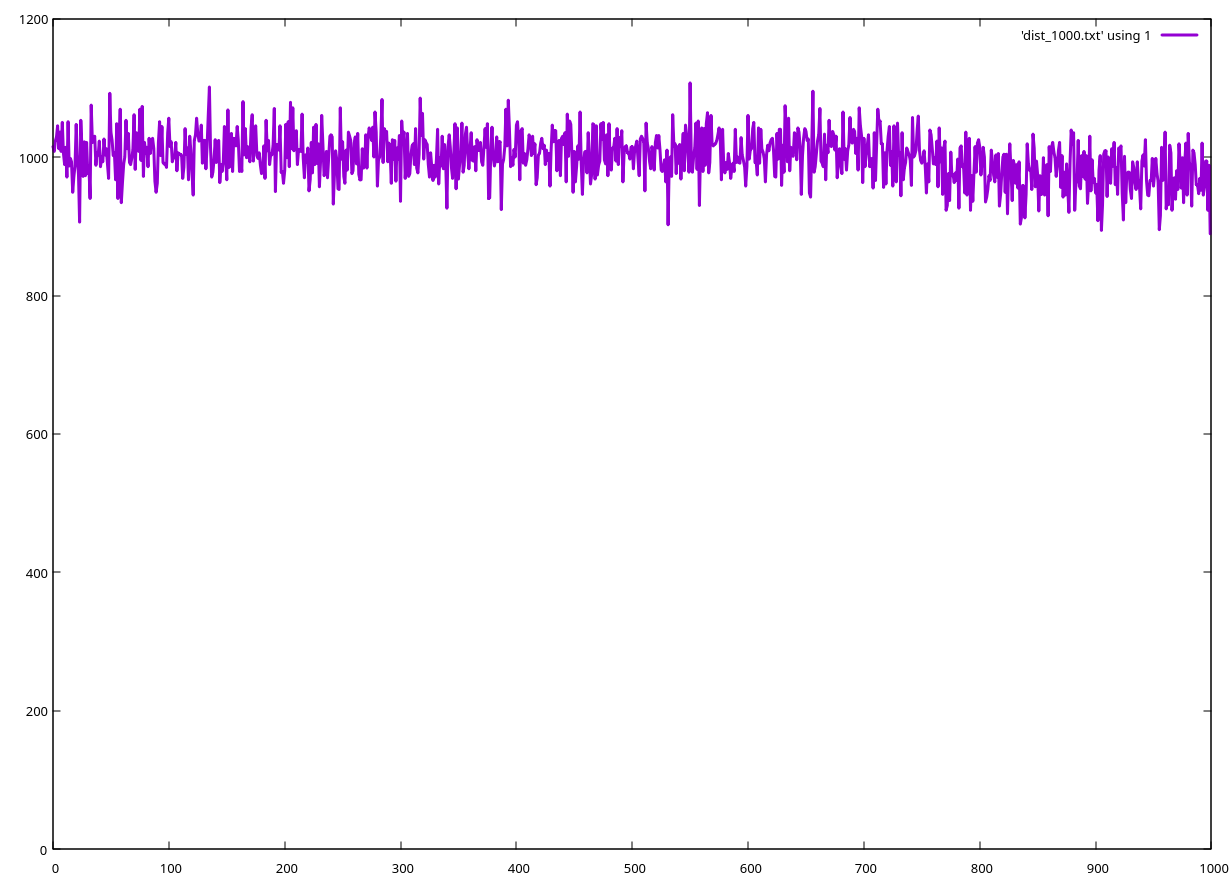
Next, with a fairly large array, consisting of 1000 elements, the bias is still noticeable, but for almost all practical purposes, it is completely negligible. It is a perfectly valid RNG for situations where one just picks an element at random from an array, but it is not applicable in areas like cryptography, Monte Carlo simulations, etc… where uniform randomness is important (and you probably wouldn’t use Bash for those, anyway). Here is the distribution (notice the slight decrease in probability towards the back of the array):
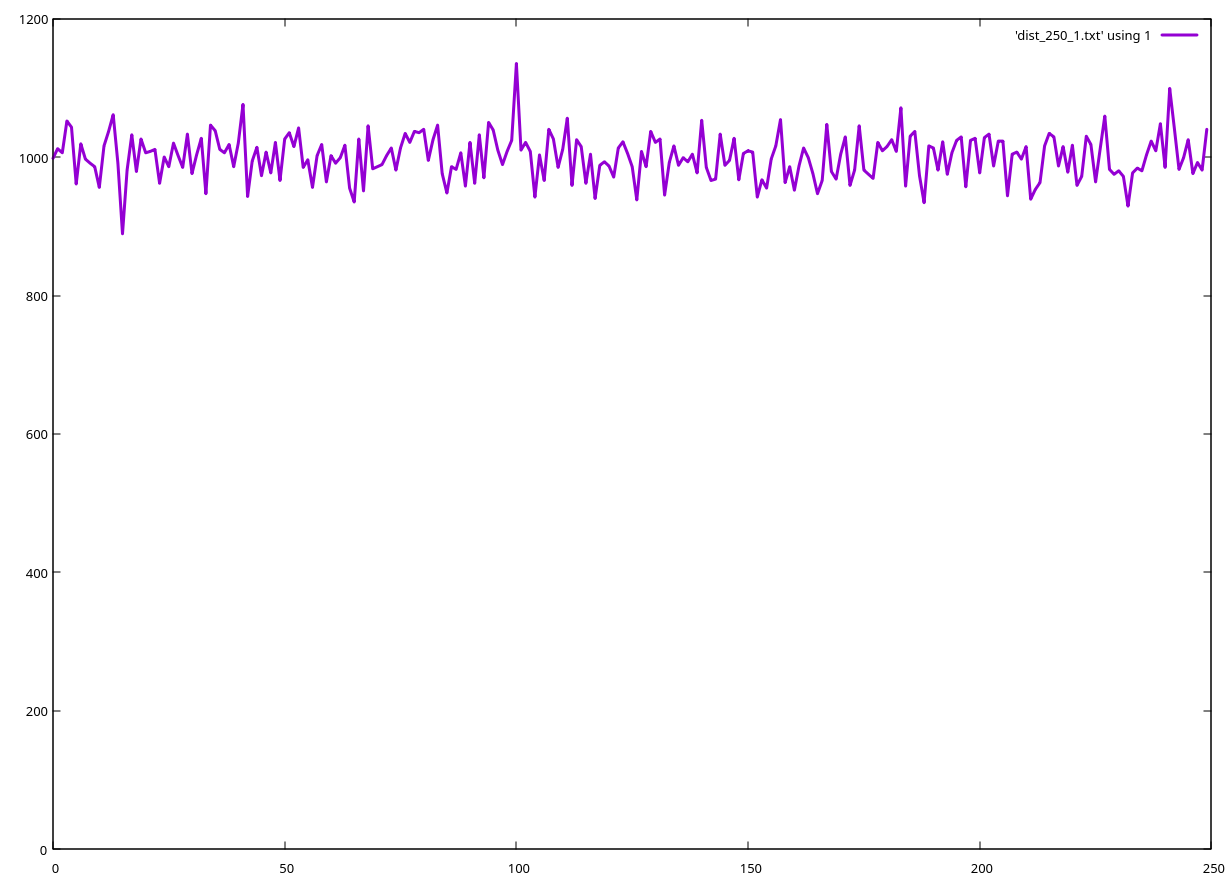
For a smaller array, consisting of 250 elements, the bias is completely gone:
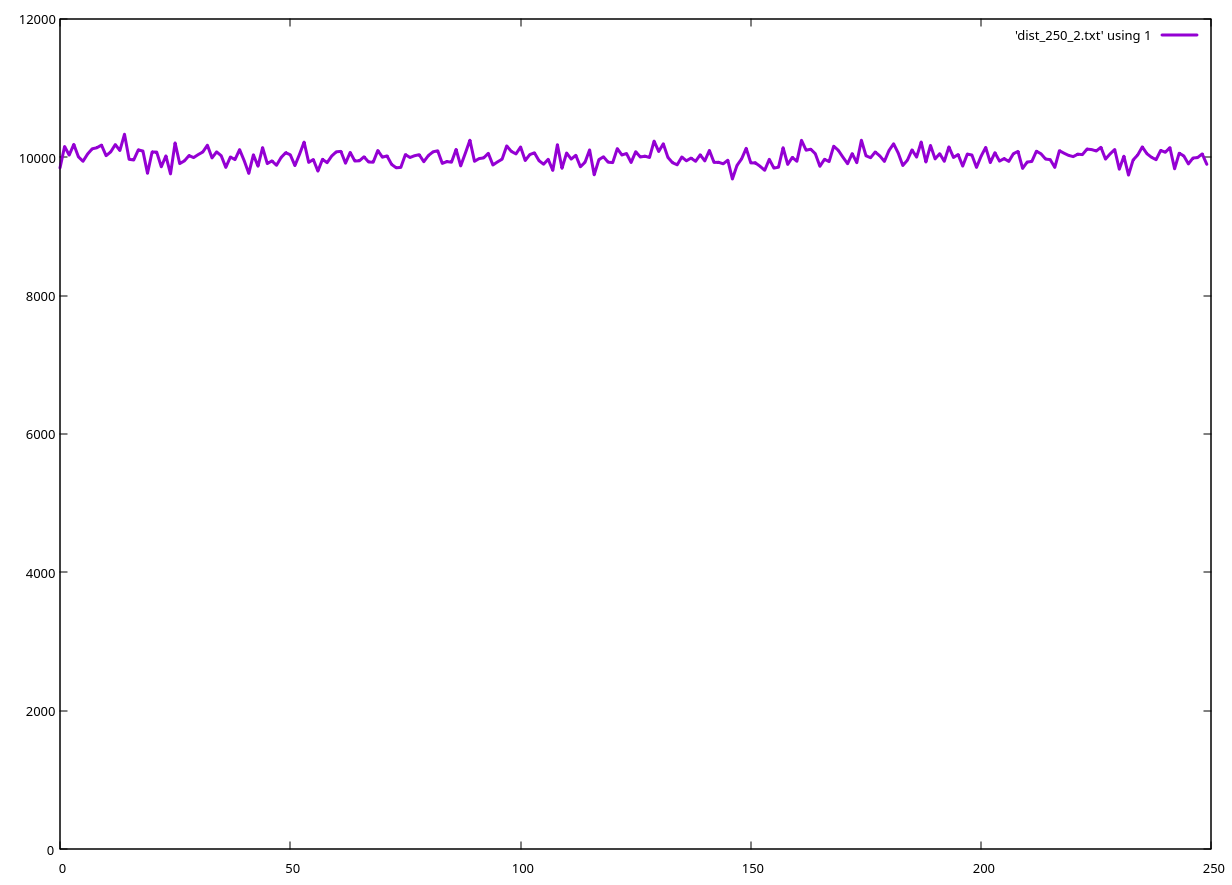
It is impossible to detect it even with a much larger sample size (which is unsurprising, since it can be shown theoretically that the bias is negligible for array sizes that use half as many bits as the max RANDOM, in this case, 2^8).
#!/bin/bash
size_of_bin=250;
for ((f = 0; f < size_of_bin; f++)); do
freq[$f]=0;
done
n_samples=$((1000*size_of_bin));
for ((i = 0; i < n_samples; i++)); do
r=$((RANDOM % size_of_bin))
: $((freq[r]++))
done
rm -f - distribution.txt
for ((f = 0; f < size_of_bin; f++)); do
echo $((freq[f])) >> distribution.txt
done
The graphs were plotted using Gnuplot.
The conclusion: unless you have a couple of thousand pictures to choose from, RANDOM % number_of_pictures is a perfectly valid way to make that choice. But even if you happen to have such a huge collection, it’s still not a problem, just make sure to put the ones you like the most at the front of the list.
That’s some fine programming excercise for 1:30 AM, right? 
Anyway it is always nice to see practical examples like this. Good work. 
Some aliases that I use:
A nice markdown editor with the code package. Make the window wide enough, then use “Ctrl-K D” to open preview too:
sudo pacman -Syu code # install code first alias md='/usr/bin/code-oss -n' md README.md
Then for those who want easier commands but don’t want to learn new names for existing programs:
alias pacdiff=eos-pacdiff # pacdiff with GUI "diffing"
Is that last very different from:
alias pacdiff='DIFFPROG=meld suc pacdiff'
in operation? Oh - and replace “suc” with “sudo” if you prefer it 
Not necessarily (if you already know your configs and envs), but eos-pacdiff takes care of many different environments and configurations as well.
Likely in your environment eos-pacdiff does about the same as your alias.
I think it mainly depends on whether I have the mouse in hand, or fingers on keyboard - now that Welcome opens on my preferred tab! Hadn’t thought of trying to call eos-pacdiff directly though… Also, sometimes I’m on a Arch-based setup without the EndeavourOS repo - though the number of those keeps shrinking!
Just out of curiosity I tried to compare execution time (user time) for the different random functions (10000 iterations with 30 repeats for some statistics).
searchword=$(echo ${searchwords[$(echo "${!searchwords[@]}" | sed -e "s, ,\n,g" | shuf -n1)]})
(31179 +/- 64) ms
searchword=$(tr ' ' '\n' <<< "${searchwords[*]}" | shuf -n1)
(14684 +/- 1345) ms
searchword=$(shuf -n1 -e "${searchwords[@]}") # yes, I found out that shuf can directly take the array as input
(5005 +/- 48) ms
searchword=${searchwords["$[RANDOM % ${#searchwords[@]}]"]}
(56 +/- 4) ms
@Kresimir, your aproach is about 600 times faster compared to my monstrosity. Not bad at all. Not sure if that is of any significance since I want to generate like 1 random wallpaper per day… 
With larger arrays (e.g. ({100…15000})) the difference is even bigger the second command is even faster than the trird one. Looks like shuf is shuffling everything even thought I just want the first element returned.
There is some overhead from for-loop and function call but it should be the same for each example. I also tested it several times and somehow that standard deviation is quite wild ranging from milliseconds to seconds.
#!/bin/bash
searchwords=({100..150})
loop_per_command=10000
loop_per_func=30
fnc_1()
{
for (( i=0; i<$loop_per_command; i++ )); do
# place your timed command inside this for loop
searchword=$(echo ${searchwords[$(echo "${!searchwords[@]}" | sed -e "s, ,\n,g" | shuf -n1)]})
done
}
fnc_2()
{
for (( i=0; i<$loop_per_command; i++ )); do
searchword=$(tr ' ' '\n' <<< "${searchwords[*]}" | shuf -n1)
done
}
fnc_3()
{
for (( i=0; i<$loop_per_command; i++ )); do
searchword=$(shuf -n1 -e "${searchwords[@]}")
done
}
fnc_4()
{
for (( i=0; i<$loop_per_command; i++ )); do
searchword=${searchwords["$[RANDOM % ${#searchwords[@]}]"]}
done
}
avg()
{
local s=0
for i in "$@";do
s=$(bc -l <<< "$s+$i")
done
echo $(bc -l <<< "$s/$#")
}
sdev()
{
local x=$(avg "$@")
local s=0
for i in "$@";do
s=$(bc -l <<< "($i-$x)^2 + $s")
done
echo $(bc -l <<< "sqrt($s/($#-1))")
}
ks=("fnc_1" "fnc_2" "fnc_3" "fnc_4")
for k in "${ks[@]}"; do
m=()
for (( j=0; j<$loop_per_func; j++ )); do
utime="$( TIMEFORMAT='%lU';time ( $k ) 2>&1 1>/dev/null )"
arrtimes+=("$utime")
m+=($(perl -CSD -Mutf8 -ne 's,(?:(\d+)h)?(\d+)m(\d+)\.(\d{3})s,(($1*60+$2)*60+$3)*1000+$4,gue; print' <<< "$utime"))
done
x=$(avg "${m[@]}")
u=$(sdev "${m[@]}")
printf "$k: (%.0f +/- %.0f) ms\n" "$x" "$u"
done

