I left it overnight, and it reported more of the same type of statements–they seem to be related to my audio out device that is plugged in to the mobo.
Yes, those are not significant events which may trigger acpi state changes to store memory snapshots in slab. Whild acpid running, acpi-state kept growing?
How did you flash your BIOS last time? Try another kernel, like LTS, maybe?
Yeah, acpi state was still growing, and is once again huge. Last time I upgraded my bios, I downloaded the new bios off of the Gigabyte website and then USB flashed from within the BIOS.
I can definitely try another kernel–will try using LTS. I also have a few more acpi related boot args to try, and would like to try toggling platform power management just in case this is related to the issue somehow.
First, I’ll try LTS without any acpi args or toggling power management.
Editing this message to make all a quote–is mostly irrelevant since the ethernet issues were fixable with the proper driver.
I was able to install linux-lts and nvidia-lts, and then to boot into it, but my ethernet connection was unrecognized in the lts kernel. So, I rebooted back to the non-lts kernel and installed an lts version of the realtek drivers with sudo pacman -S r8168-lts. Then I rebooted into linux-lts, and now neither lts nor regular linux have connectivity.
For some reason, I then decided to nuke my install and start from scratch, so I reinstalled a fresh eOS with a fresh iso from a flashed USB. The live boot from the USB connected via ethernet and installed from the internet, but once installed, booting into lts again gives no internet. However, booting into regular arch-linux connects normally.
Neither of these commands show any output:
pacman -Qs r8168
pacman -Qs r8168
I’ve also tried restarting NetworkManager, which appears to be active.
I suppose I could try tethering with my iphone via USB as well?
I tried a fresh install of arch-linux (non LTS) and eOS, but my slab was still climbing.
I finally was able to boot into the LTS kernel with connectivity, thanks to installing the r8125 realtek driver by putting the installation files on another USB and connecting it to the computer (I should have simply done this before nuking my earlier system instance, but I digress).
Depending on the system and usage pattern 2 to 3 GB of slab are still normal/fine. Depends where it is allocated. But if there’s an additional zero eventually things probably didn’t improve.
Noted! It’s currently already at 7.5gb, and seems on track for the same constant increase (maybe is even faster than before?) I did check Acpi-State again as well:
sudo sh -c "sync; echo 3 > /proc/sys/vm/drop_caches" doesn’t much impact total memory usage. It’s been a few hours since checking, and now slab is over 20Gb. I forgot to run free -h before, but here is the output after running it (htop memory bar doesnt change)
[wes@wes-wks Downloads]$ sudo sh -c "sync; echo 3 > /proc/sys/vm/drop_caches"
[wes@wes-wks Downloads]$ free -h
total used free shared buff/cache available
Mem: 125Gi 25Gi 100Gi 230Mi 982Mi 99Gi
Swap: 8.8Gi 0B 8.8Gi
This was definitely an issue before I configured swap as well (I had hoped swap would somehow fix this). Well, I will keep trying acpi related boot args from the list above
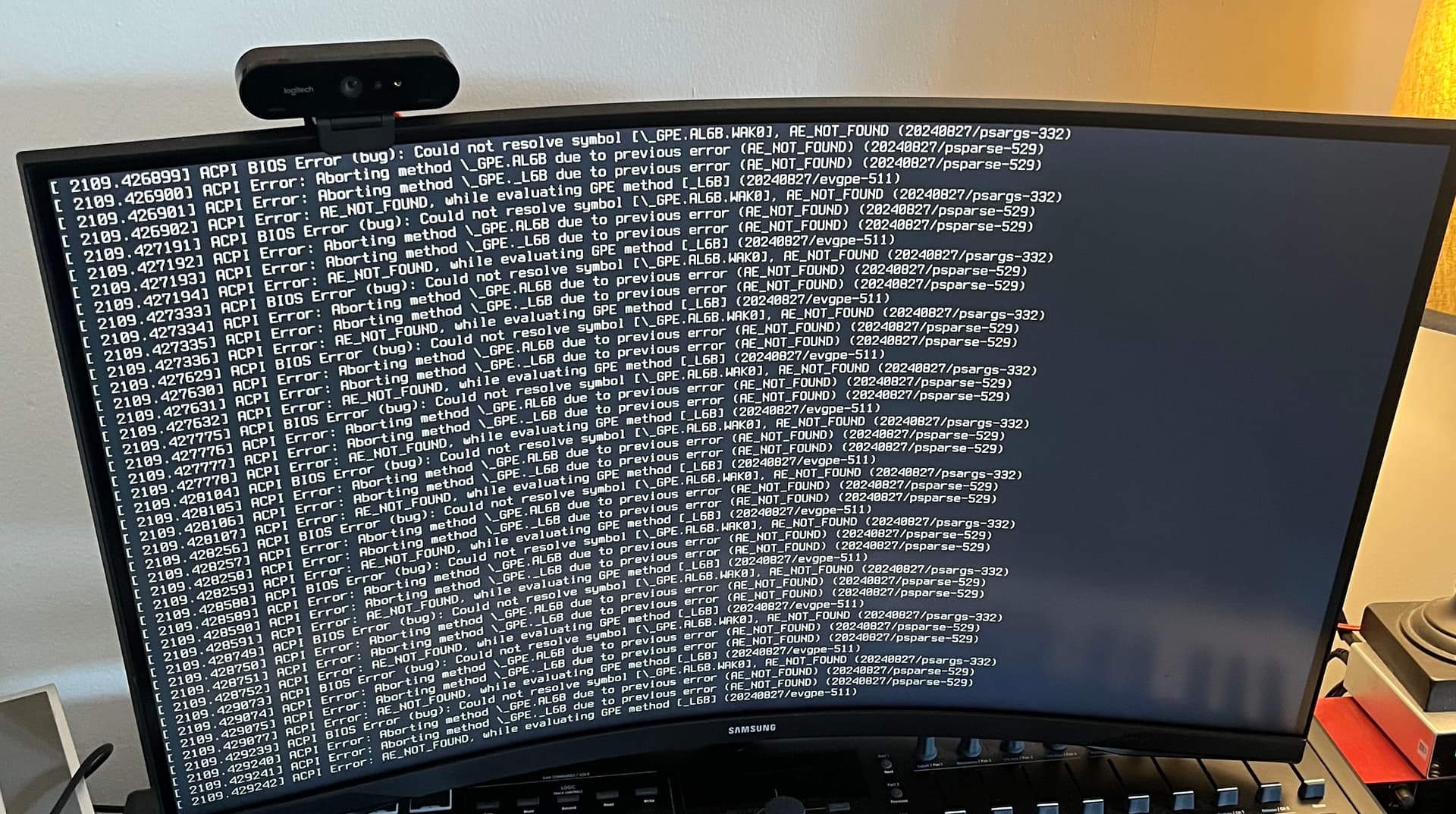
Update: Now that I am booting into a fresh install of EOS (I’m using lts kernel as well), I am no longer using the “quiet” boot arg. Now, when my device goes to sleep, I see a bunch of ACPI messages on the display. The messages are not scrolling, but I wonder if this gives any clues about the issue. Slab seems to be growing uncontrollably again.
I’ve also disabled XMP and enabled platform power management in the bios on this boot. (However, these acpi error messages were also happening on the previous boot with PPM disabled and XMP enabled).
Try to boot from a Debian stable Gnome live image. If the problem persists, get the BIOS firmware from the manufacture site and flash your BIOS again. If all steps don’t work, report the bug to the manufacture.
So after re-flashing the BIOS and trying multiple other distros including debian stable, I’m finding that the slab cache tends to increase regardless. In one instance, I saw that Acpi-Parse slab cache was exploding in size rather than Acpi-State (maybe a distribution difference). I called Gigabyte, and they say the CPU is what controls memory.
They suggested I try just 2 memory sticks in slots 2 and 4 and then try the other 2 sticks in the same slots, to see if the same issue persists. If neither of these configurations solve the problem, they say I should try just 1 memory stick in slot 2 (trying all 4 sticks) and then doing the same for slot 4. That’s 10 boots, when this issue seems to require at least 6-10hrs (effectively most of a day) to replicate. It seems they do not think they could be responsible for this, regardless.
(I have only a tentative notion of all the technical details that I’ve read in this thread, but it’s impressive to see how people here have dug in to help, and how you keeps trying out suggestions and options.
I hope you get it triaged and hopefully even solved!)
The QVL list for this motherboard does not include these exact sticks. They are well reviewed and non-niche memory sticks though–The QVL list has a whole page of other Patriot sticks that are verified, but none are at this high capacity (probably because there is less demand for high memory capacity).
I realize you commented earlier in this thread and mentioned it might be worth checking memory support by the MOBO–very prescient! Hopefully these sticks not being on the list doesnt stop me from making a trade/return, if the memory is somehow the problem.
Probably because they didn’t test those high capacacity type of sticks would be the reason why they don’t take responsibality I guess. But ofcourse if there is a problem with the memory it could as well be a problem with the slots they are placed in.
Hopefully the process of testing the different RAM sticks and slots will clarify some things and give a clue as to whether one/some of the slots or one/some of the sticks have an issue, but I agree that it would be unfortunately hard to know what is happening if all of the slots or all of the sticks have an issue. If this is the case, I guess I’d hope the RAM manufacturer lets me return the sticks, or that Gigabyte lets me exchange/return the MOBO? I expect they’d give me a hard time for using unsupported memory, and I also worry that they’d again point out that “the CPU controls memory”.
If the RAM sticks are pair1: (1, 2) and pair2: (3, 4) and the slots are (A1, A2, B1, B2), I’ve tried (1 x A2, 2 x B2) and (3 x A2, 4 x B2) excuse my weird enumeration.
In both cases, the slab grows out of control. But, I’m noticing that the slab seems to stay pretty low initially and only eventually starts to skyrocket.
I’ve never done something like this, but it feels useful to put together a cron job that auto records slab size every hour as well as uptime. It also seems like the growing slab might be triggered by the computer waking up from sleep–I’m going to try booting and disabling sleep to see if this helps.
*If anyone knows a way to create a cron job that tracks Slab every hour and maybe even auto-gen/save a graph, I’d be super grateful
I found a related post to slab growth after sleep–will link to it when I get home later.