Hey everyone, after using Debian-testing for a week and a half (my longest consistent period ever on a linux machine, I’m a new-comer who finally decided to make the transition from Windows).
Without further ado, while installing EndeavourOS (two days ago) I choose to install the LTS kernel during the setup (because I’m very afraid of Arch and Arch-based distros, the crazy amount of online posts I’ve read of people who moved away for unstability and PC’s not booting after updates and what not so I realized that maybe having the LTS kernel available is a good practice?)
On installation day, no problems at all apart from apart from SDDM hanging on shutdown (KDE Wayland) which I realized can be fixed by actually shutting down through the GUI.
Next day I get up to boot my PC and I get a kernel panic message, after looking online I came across a post where someone didn’t boot after connecting ethernet cable or something like that? So I looked at the connected devices to my PC that weren’t plugged the other day, I spotted an old wifi-adapter my brother was trying out so I thought maybe that’s it. Unplugged, restarted, PC works like a charm, it’s literally too good to be true.
Almost true. Later that same day (yesterday), I shut down my PC and went out for four to five hours or so, when I came back and fired up the PC, here it was, the kernel panic again. I just hanged on the screen searching through loads of various topics online, people are getting the same crash as me;
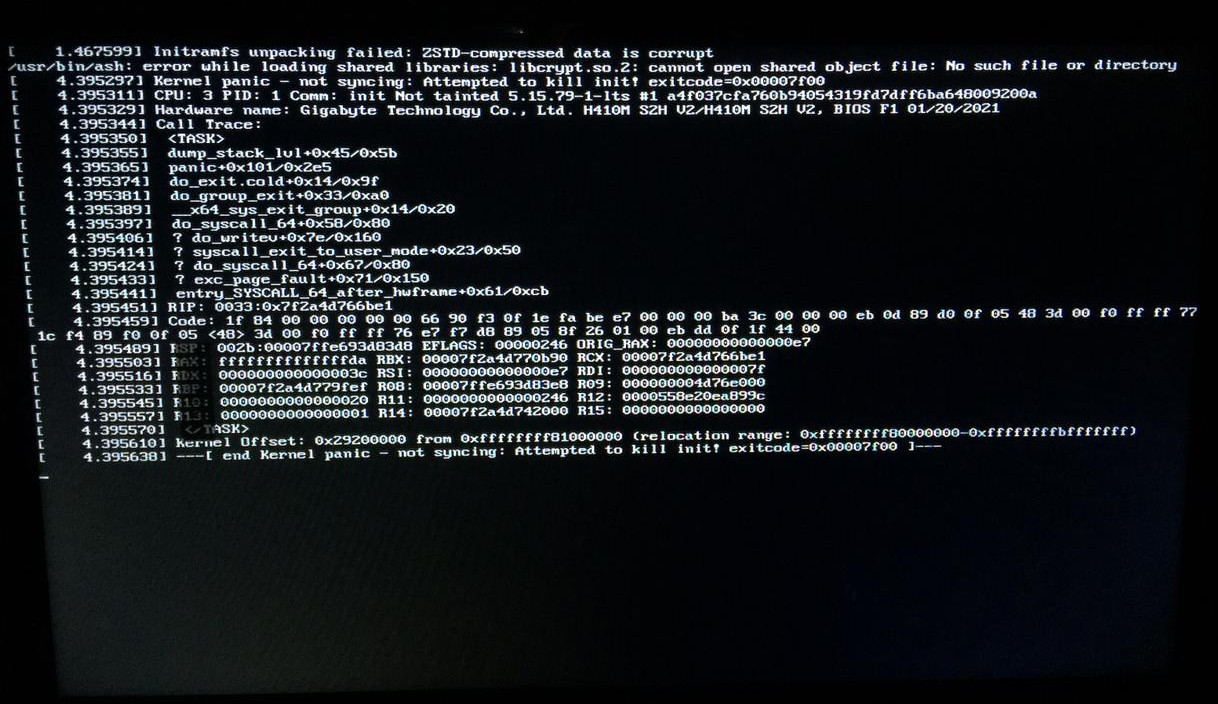
"initramfs unpacking failed: ZSTD-compressed data is corrupt"
but it’s the second part “ZSTD-compressed data is corrupt” that’s different for them.
Long story short, after two hours of surfing the web I stumbled upon a reddit post of someone on ArchLinux who had the same problem, a user asked them about a tool called “mkinitcpio” that I had no idea what it was so I looked it up, realized it’s related to create the initial ramdisk enviroment that supposedly handles stuff for init then I remember when I manually chose to grab the LTS on EOS installation so I was like maybe that’s it? Perhaps the installation forgot to use the tool in question? At this point I just hit the reboot button in my PC and once again, the PC started to life although I did see a glimpse of the error in the very beginning of package loading however, no kernel panic.
I ran the command
sudo mkinitcpio -P
after the computer started then shutdown my PC entirely, waited for 5 minutes or so trying to reproduce the problem, which sadly worked, the kernel panic wasn’t solved and I slammed restart once again my PC boots fine on the reboot.
My brain lurched at this point so I just went to sleep and woke up next day (today), went to college and didn’t touch my PC in the morning. However I was struck by an idea, maybe I should use the other kernel that comes preinstalled with EOS? Perhaps this fixed the problem entirely? Which I think it did for a single boot, then the problem reoccured but now it’s a different error (I think?).
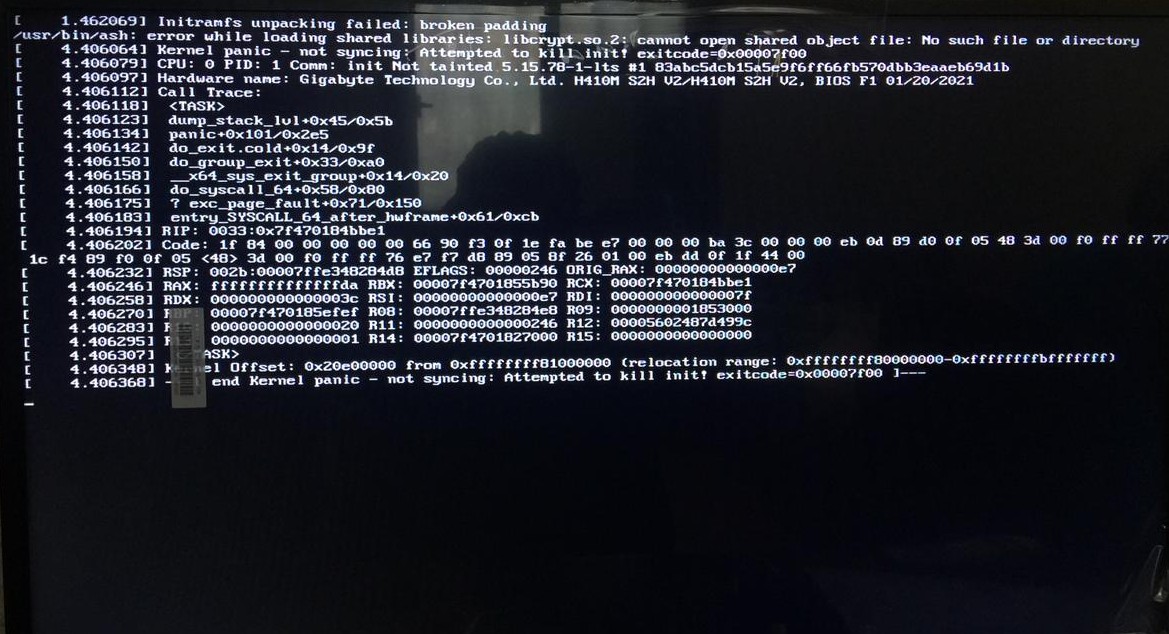
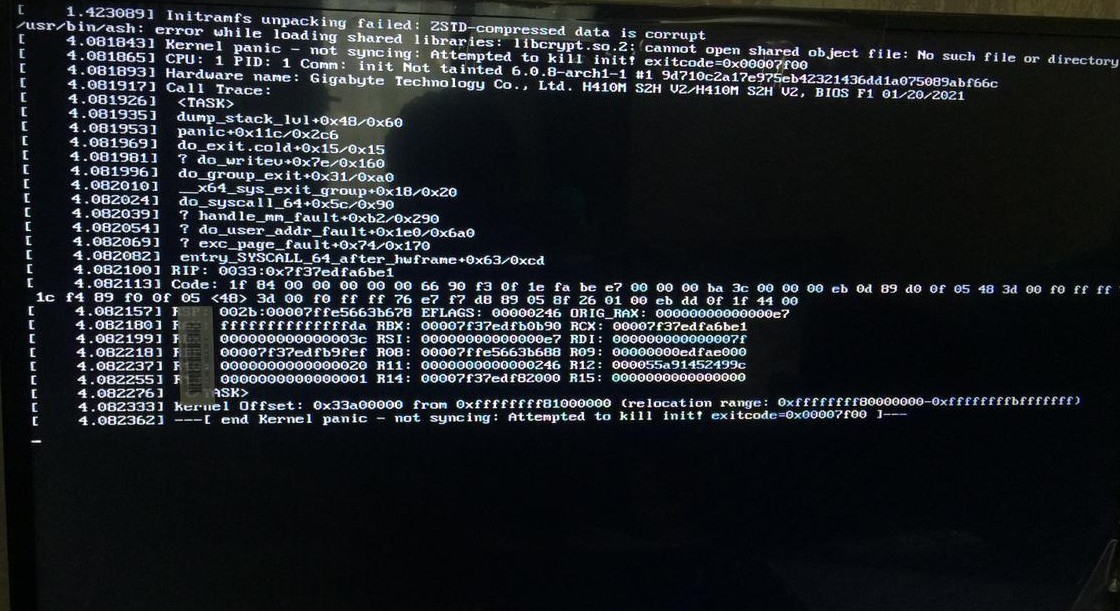
The two images I uploaded should provide better information on the two errors I face currently whenever I do a cold boot, a reboot just starts the system no matter what kernel I pick. This is frustrating to be honest and I’d be extremely sad if it’s a hardware problem given that I bought my current PC build only a year ago or so so yeah. That’s it.
Any help is appreciated and thank you for making it this far into the post.