Thanks for your post sharing your insights!
I’ll keep an eye on journald.
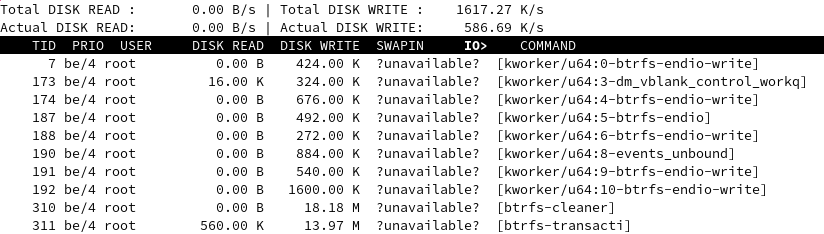
In the meantime, I removed all occurences of (no-)autodefrag from the /etc/fstab as @mcury had done earlier but in my case, after reboot btrfs-transacti is still there:

![]()
Same here…

Alright!
You said earlier that
so I was wondering.
Seemingly btrfs-transacti seems to be unrelated to the defrag issue.
It appears and then disappears, when I looked at the first time it didn’t show up… So sorry for that, my mistake there…
No problem!
It shows up every 30 seconds apparently.
yes this is what I do see also ![]()
But there is no way to inform aside from Forum Telegram Twitter.
Remember that the background processes are a normal piece of functionality, i.e. any disk writes will use the same process names.
Garuda has a handy background notification applet that regularly checks for news - might be something to look at, though it’s not really a “minimal” approach to things.
Is any Hotfix possible in this case also to remove the autodefrag option in /etc/fstab from Calamares?
I suppose running the LTS kernel for a while is enough?
LTS is 5.15 right?
yes we do work on that already.
Yes, I think so.
Perhaps switching to the LTS is a good option for now.
Transaction is just a fancy word for “data moved by the filesystem”. So btrfs-transaction is a normal part of btrfs and always there. If there’s a lot of activity than btrfs-transaction also starts working. If there’s an unusual high traffic for whatever reason (e.g. defragmentation) btrfs-transaction lights up too. That’s OK.
This is certainly possible but I hate the idea of globally modifying an installed systems configuration like that.
Thanks for the explanation!
I kind of started realizing that it is part of the proper working of the filesystem. Your explanation makes it all more clear.
Strange, running LTS, with the autodefrag option, didn’t solve the problem…
$ uptime
11:30:49 up 5 min, 1 user, load average: 0,57, 0,66, 0,36
uname -a
Linux eos 5.15.18-1-lts #1 SMP Sat, 29 Jan 2022 12:13:13 +0000 x86_64 GNU/Linux
You can’t get rid of all filesystem transactions - that’s a normal part of filesystem activity.
If you reenabled autodefrag then there will be more activity than without because it’s defragging in the background.
If that means messing with peoples fstab config it’s probably a big can of worms.
And as I said when I encountered the issue it only affected one out of multiple disks, so it’s not even a potential “let’s fix an horrible outcome for everyone” situation. Also it settled down after a while to a few MB per minute.
If a fix is coming in 5.16.4 and it doesn’t affect 5.15 LTS imho an intervention does more harm than good. If it was a huge issue we would have heard more about it in the last few weeks.
It would be possible to modify the welcome app to display important messages and ask to apply a fix.
The updated kernel would likely be available before there was time to build and test that properly.
Ultimately, this isn’t a fix, it is a workaround.
Sure, but it might happen again.
Edit: And applying that fix would not even have to be automatically. It could just be the file, configured in a way it’s supposed to be better. And then you could open vimdiff or whatever and apply the fix yourself.
But this whole discussion is OT in this thread.