I’m running ollama-cuda to run a local language model on my gpu. It happily gobbles up my VRAM, but the gpu utilization stays at 0-2% indicating that it is in fact not gpu accelerated.
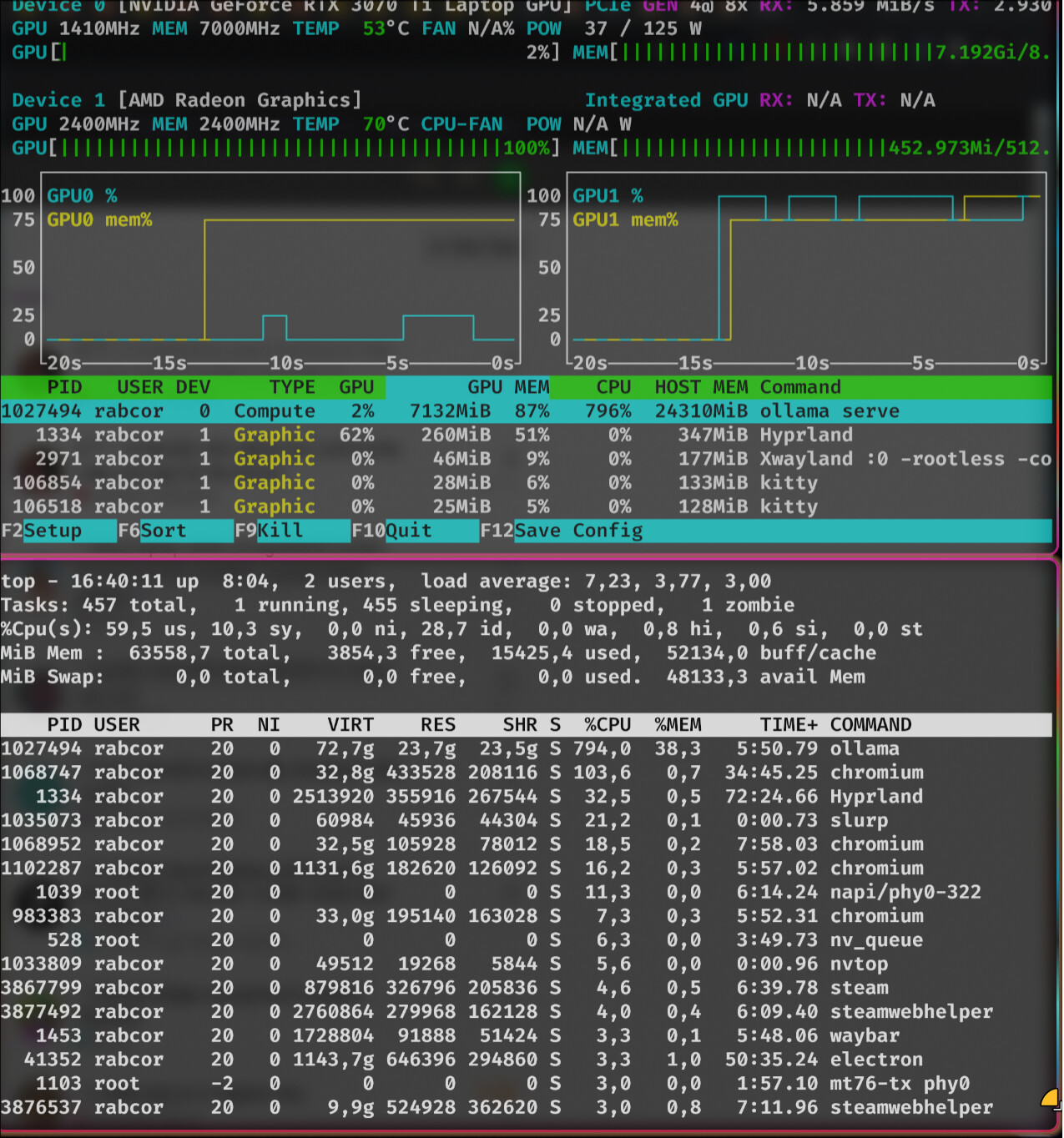
And here is it’s output which does say it should be gpu accelerated (i only included relevant parts, e.g. parts mentioning gpu or cuda somewhere within them, there were no errors, but there was a warning which is included.):
Output
2024/01/27 16:39:08 payload_common.go:145: INFO Dynamic LLM libraries [cuda_v12 cpu cpu_avx2 cpu_avx]
2024/01/27 16:39:08 gpu.go:91: INFO Detecting GPU type
2024/01/27 16:39:08 gpu.go:210: INFO Searching for GPU management library libnvidia-ml.so
2024/01/27 16:39:08 gpu.go:256: INFO Discovered GPU libraries: [/opt/cuda/targets/x86_64-linux/lib/stubs/libnvidia-ml.so /usr/lib/libnvidia-ml.so.545.29.06 /usr/lib32/libnvidia-ml.so.545.29.06 /usr/lib64/libnvidia-ml.so.545.29.06]
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
WARNING:
You should always run with libnvidia-ml.so that is installed with your
NVIDIA Display Driver. By default it's installed in /usr/lib and /usr/lib64.
libnvidia-ml.so in GDK package is a stub library that is attached only for
build purposes (e.g. machine that you build your application doesn't have
to have Display Driver installed).
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Linked to libnvidia-ml library at wrong path : /opt/cuda/targets/x86_64-linux/lib/stubs/libnvidia-ml.so
2024/01/27 16:39:08 gpu.go:267: INFO Unable to load CUDA management library /opt/cuda/targets/x86_64-linux/lib/stubs/libnvidia-ml.so: nvml vram init failure: 9
2024/01/27 16:39:08 gpu.go:96: INFO Nvidia GPU detected
2024/01/27 16:39:08 gpu.go:137: INFO CUDA Compute Capability detected: 8.6
[GIN] 2024/01/27 - 16:39:08 | 200 | 72.506µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/01/27 - 16:39:08 | 200 | 2.094985ms | 127.0.0.1 | GET "/api/tags"
[GIN] 2024/01/27 - 16:39:14 | 200 | 23.054µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/01/27 - 16:39:14 | 200 | 392.387µs | 127.0.0.1 | POST "/api/show"
[GIN] 2024/01/27 - 16:39:14 | 200 | 253.937µs | 127.0.0.1 | POST "/api/show"
2024/01/27 16:39:14 gpu.go:137: INFO CUDA Compute Capability detected: 8.6
2024/01/27 16:39:14 gpu.go:137: INFO CUDA Compute Capability detected: 8.6
2024/01/27 16:39:14 cpu_common.go:11: INFO CPU has AVX2
loading library /tmp/ollama1142629703/cuda_v12/libext_server.so
2024/01/27 16:39:14 dyn_ext_server.go:90: INFO Loading Dynamic llm server: /tmp/ollama1142629703/cuda_v12/libext_server.so
2024/01/27 16:39:14 dyn_ext_server.go:139: INFO Initializing llama server
system info: AVX = 1 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 0 | ARM_FMA = 0 | F16C = 0 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3070 Ti Laptop GPU, compute capability 8.6, VMM: yes
llama_model_loader: loaded meta data with 22 key-value pairs and 543 tensors from /home/rabcor/.ollama/models/blobs/sha256:5dec2af2b0468ea0ff2bbb7c79fb91b73a7346e0853717c9b7821f006854c9bb (version GGUF V3 (latest)1
...
...
llm_load_tensors: using CUDA for GPU accelerationn
llm_load_tensors: system memory used = 16760.45 MiB
llm_load_tensors: VRAM used = 6433.44 MiB
llm_load_tensors: offloading 17 repeating layers to GPU
llm_load_tensors: offloaded 17/61 layers to GPU
These warnings also seem unrelated, but I get them as well
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
Also sometimes when i try to run ollama-cuda it’ll crash complaining about being out of vram, but when that happens it’s supposed to just use the system RAM instead, or so i hear.
There’s little point to using the vram if i’m not using the gpu as well.