Hello everyone,
Yesterday ever since doing my regular yay (which included updates for the kernel and NVidia driver) and rebooting, I’ve gotten a black screen with a moving cursor after logging in (SDDM) and getting pass the KDE splash screen. Using both Xorg and Wayland session brings the same results. I cannot open anything as nothing is displayed and I can only access the terminal through ctrl+alt+F4.
So far, I have tried:
fscking my root partition through a bootable Arch iso,- restoring a snapshot of my root from before the update using Timeshift,
- downgrading all the
endeavouros, core, extra and the 32bit packages to the date of few days ago (as instructed here in Arch wiki),
Neither of which has worked (which is interesting because the problem started after the system upgrade and I thought downgrading/restoring a snapshot would help.)
Log for inxi -Fxxc0z:
http://0x0.st/XXI9.txt
Log for journalctl -b -0:
http://0x0.st/XXI2.txt
In the journal, there are many errors from dbus-broker-launch and dbus in general like this:
May 04 21:03:24 dbus-broker-launch[659]: Service file ‘/usr/share/dbus-1/services/org.kde.dolphin.FileManager1.service’ is not named after the D-Bus name ‘org.freedesktop.FileManager1’
but I don’t what causes it, if it’s the root cause of the black screen or how to fix it.
So any help is appreciated. Thanks in advance!
Hello, and welcome to EnOS community 
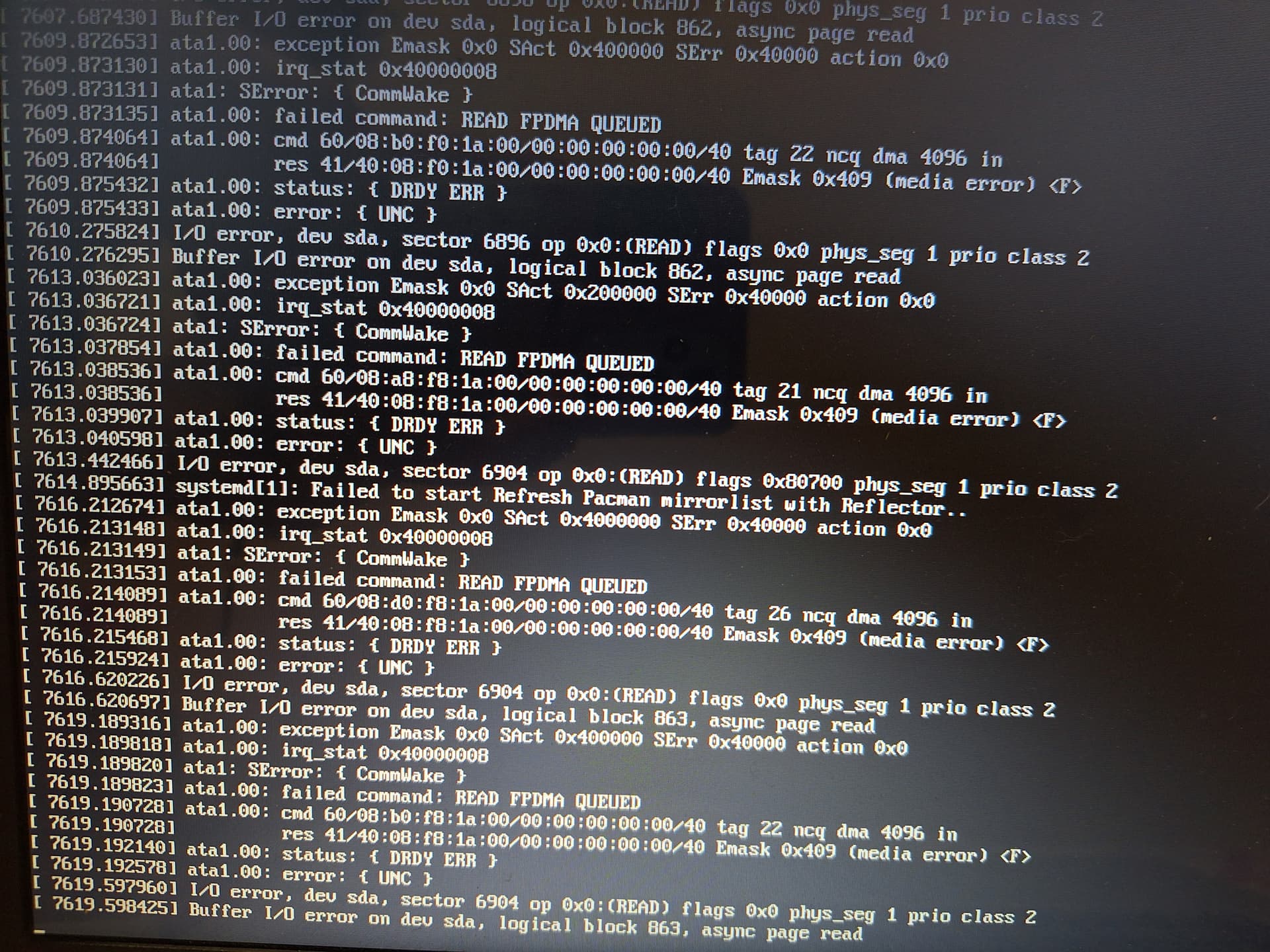
Your journal is full of disk read errors and coredumps of processes that are trying to read from the “bad block/sector” on the drive. KDE services crash after you login, and that’s why you see a black screen.
Drive is initialised at UDMA/133
May 04 21:03:12 depongo kernel: ata1: SATA max UDMA/133 abar m2048@0xdf333000 port 0xdf333100 irq 125 lpm-pol 3
May 04 21:03:12 depongo kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
Then read exception occurs, and its reconfigured to UDMA/100 (probably kernel trying to recover)
May 04 21:03:39 depongo kernel: ata1.00: exception Emask 0x0 SAct 0x100 SErr 0x40000 action 0x0
May 04 21:03:39 depongo kernel: ata1.00: irq_stat 0x40000008
May 04 21:03:39 depongo kernel: ata1: SError: { CommWake }
May 04 21:03:39 depongo kernel: ata1.00: failed command: READ FPDMA QUEUED
May 04 21:03:39 depongo kernel: ata1.00: cmd 60/10:40:d0:80:50/00:00:20:00:00/40 tag 8 ncq dma 8192 in
res 41/40:10:d0:80:50/00:00:20:00:00/40 Emask 0x409 (media error) <F>
May 04 21:03:39 depongo kernel: ata1.00: status: { DRDY ERR }
May 04 21:03:39 depongo kernel: ata1.00: error: { UNC }
May 04 21:03:39 depongo kernel: ata1.00: configured for UDMA/100
And it finally fails with I/O error
May 04 21:03:54 depongo kernel: sd 0:0:0:0: [sda] tag#13 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK cmd_age=3s
May 04 21:03:54 depongo kernel: sd 0:0:0:0: [sda] tag#13 Sense Key : Medium Error [current]
May 04 21:03:54 depongo kernel: sd 0:0:0:0: [sda] tag#13 Add. Sense: Unrecovered read error - auto reallocate failed
May 04 21:03:54 depongo kernel: sd 0:0:0:0: [sda] tag#13 CDB: Read(10) 28 00 20 50 80 d0 00 00 08 00
May 04 21:03:54 depongo kernel: I/O error, dev sda, sector 542146768 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
May 04 21:03:54 depongo kernel: ata1: EH complete
Check the SMART status of your disk, run
sudo smartctl -a /dev/sda
Run a fsck of your root drive. Boot into a live ISO and run a check from there.
You can also try to disable NCQ by adding libata.force=noncq to kernel command line, and see if the read errors will go away.
Good luck!
Hello and thank you for your reply and suggestions.
I once again ran fsck for the root partition from an Arch ISO and it was clean (as i had done it before.)
This is the output of sudo smartctl -a /dev/sda:
http://0x0.st/XXD9.txt
It seems that, as you said, there are many many errors regarding bad sectors in the SMART report. I don’t know what could have caused it and if it’s a hardware HDD issue or not (and how to prevent this in the future.)
I also booted with the noncq kernel parameter in the grub command line but unfortunately the screen freezes at the KDE splash screen.
This is journalctl -b -0 after adding libata.force=noncq:
http://0x0.st/XXkt.txt
I appreciate any suggestions.
SMART self-check status shows unrecoverable read error occurred (confirming a bad block)
Error: UNC at LBA = 0x005080d0 = 5275856
The other worrying thing is pending sector count SMART attribute
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 208
There are 208 pending sector reallocation requests, but zero reallocated events. That means that disk firmware is not able to remap the bad blocks and “unstable” sector count just keeps growing.
What I would try to do next is backup any important data if possible, then wipe and zero-out the drive, and then test for bad blocks again.
While in the live ISO environment make sure your drive is unmounted and run
sudo dd if=/dev/zero of=/dev/sda bs=1GB # zero-out the drive
sudo badblocks -n /dev/sda # non-destructive test for bad blocks
Hopefully this will help the firmware mark the bad blocks correctly.
I just successfully zero-ed the disk with no errors from dd but badblocks -n is showing many many sector errors.
As I was running dd and badblocks, systemd core dump errors were constantly appearing and littering the logs, therefor I can not provide a clean and clear text output of the errors here.
Is it somehow possible to silence these coredump errors for now?
Regardless, here are two snippets of the badblocks -n errors at two different times (BADBLOCKS 1 and BADBLOCKS 2) plus a snippet of the coredumps littering the logs (BADBLOCKS 3 + COREDUMPS).
Please don’t hesitate to ask for more logs/snippets If they’re not sufficient or clear enough. I can give a full output when I figure out how to ignore the coredumps.
Thank you again.
BADBLOCKS 1
BADBLOCKS 2
BADBLOCKS 3 + COREDUMPS
Yes, this is expected, no need to see more logs. Hopefully live ISO environment has not crashed and badblocks command finished.
Can you run smartctl again and check Current_Pending_Sector and Reallocated_Event_Count?
If the pending sector count has not decreased, I’m afraid you will need to replace your drive
Apologies for the late reply.
I have switched to a SSD since then. I will be getting a SATA cable soon to check if the pending sectors have decreased or not. But until then, I think we can most likely declare it dead!
Thank you regardless. So I think I should mark this topic as solved.