hmm, so it is required to include nested subvolumes into BTRFS_DEFRAG_PATHS…
I wasn’t aware of that…
1 Like
That doesn’t sound logical to me at first. I would have rather assumed the opposite.
It is because compression on a modern CPU has very little overhead and is fast when you are talking about the type of compression you would use on a filesystem(lz4,zstd at low compression levels).
Conversely, writing and reading data to a disk is slow. So in many cases compression overhead + disk i/o compressed is faster than disk i/o uncompressed. This is especially true if your disks are slow like an HDD.
Of course, there are a lot variables involved so better to see for yourself if there is any improvement in your specific use case.
1 Like
Thanks. I need to dig into this topic. I see that BTRFS is now a safe choice over EXT4.
OK, I have enabled the tasks in the settings now. It seems to run via cron as I now have /etc/cron.daily/ and /etc/cron.hourly/ (snapper) entries. However, cronie is not installed on my machine. So should I either still install cronie afterwards or rather set it up with systemd service?
This. Use the systemd services.
Sorry for the stupid question: how do I do this? And then can delete the entries cronie entries in /etc?
sudo systemctl enable --now btrfsmaintenance-refresh.path
That watches for changes in the config file. If you are already done changing the config file you might want to run this one time:
sudo systemctl start btrfsmaintenance-refresh.service
1 Like
@dalto are these retention settings ok?
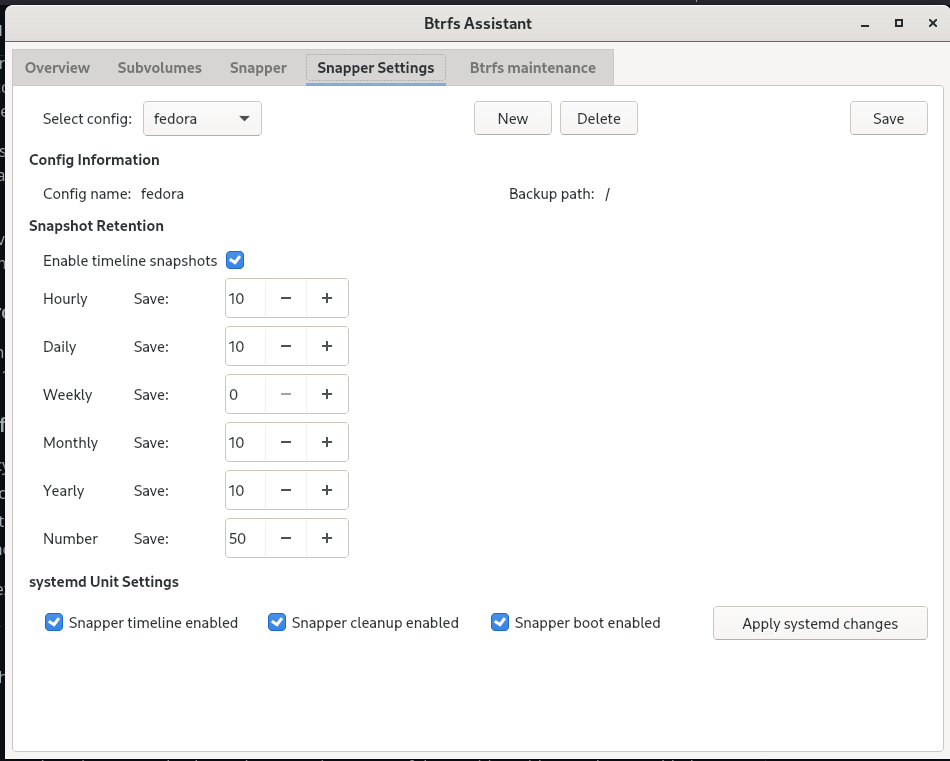
Is there any difference between restoring snapshots from systemd and grub in the btrfs assistant?
Are there any suggested settings for snapper?
@dalto What about the cronie folders in /etc/cron.daily/ and /etc/cron.hourly/, which each contain a snapper file? As I said, cronie is not installed. If these entries were created during the installation of Snapper, then they do nothing without cronie …
You can delete them but they will probably just come back next time the package is updated. I would just ignore them. There are actually a lot of packages that do that unfortunately.
1 Like
Very strange … ok, I ignore them …
Should the defragmentation be activated in the Btrfs maintenance settings? I know about the necessity, but I have also heard several times that it only harms an SSD because it creates too many extra write cycles?
I have not been able to find good reliable information on this. Generally speaking, you don’t need to defrag SSDs. However, I have read several statements that state that this is not true with btrfs since what you are defragmenting is not the disk itself. None of those statements come from official sources.
Personally, I do not defrag my btrfs filesystems on SSDs.
2 Likes
Then I will keep it that way. After all, regular defragmentation generates many more write accesses, which only shorten the SSD’s lifespan unnecessarily.
So, hi there. I’ve spent two weeks reading current tests, datasheets, reliability tests and bug reports. This is my recommendation, which I can share. Feel free to use/ignore.
disk types:
[hdd]
- good: in-place/same place overwrites (journalFS)
- bad: new copies(adds to fragmentation) (log/cowFS)
- high: impact of fragmentation(structural chaos), defrag. req.
- good: heavy writes (write amplif)
- low: device reliability (low-bad;high-good)
- low: data corruption chance (low-good;high-bad)
[sdd]
- ok*: in-place/same place overwrites (journalFS) (*controller remaps; but wrts whole blk)
- good: new copies(adds to fragmentation) (log/cowFS)
- low: impact of fragmentation(structural chaos), defrag. req.*
- bad: heavy writes (write amplif)
- high: device reliability (low-bad;high-good)
- high: data corruption chance (low-good;high-bad)
* very frequent random write->low-level fragmentation->slow down/reduce device life; log/cowFS's prevent it (f2fs whitepaper).
[nand-usb/flash//controllerless ssd]
- very bad: in-place/same place overwrites (journalFS)
- good: new copies(adds to fragmentation) (log/cowFS)
- low: impact of fragmentation(structural chaos), defrag. req.
- very bad: heavy writes (write amplif)
- medium: device reliability (low-bad;high-good)
- high: data corruption chance (low-good;high-bad)
#ext4
#xfs
#f2fs
#nilfs2
#btrfs
#ext4
- journaled (metadata/full)
- high metadata integrity (sane checksums)
- very capable fsck
- usually fixes shore data writes (power cut off)
- doesn't report or check already written data for errors
- can't self-heal, only truncate corrupted files that it manages to detect
- writes twice and discards one copy (not good for ssd)
- old table structure, slow on small files, average on large
-- for hdd and ssd+controller with no security, slower than xfs, but more resistent to fs corruption
-- ssd+controller with low TBW: best system filesystem until ssd starts corrupting data; this will come as surprise
-- hdd: best fs for system partition
-- nand-usb/flash: worst filesystem
#xfs
- journaled (metadata only)
- lower metadata integrity than ext
- slow on small files, fast on large files, very fast on single thread linear writes
- doesn't report or check written data writes
- can't self-heal, only truncate corrupted files that (if) it manages to detect
-- for..: like ext4, faster, but less resistent to errors
#f2fs
- cow/log
- compared to nilfs: multihead version with cold/hot detection
- does not track or check write errors in existing data
- minimizes metadata updates with multiple inline inodes
- two checkpoints to secure current state, not very fault proof
- rollback and rollforward support
- very weak fsck, but many improvements accepted since 2019
- automatic trim, yet trims more often than nilfs
- instabilities in kernel, instability on unclean shutdown
-- ideal for integrated power-backuped ssd with controller with no requirement for data security (app runtime, cache, cached data) - mobile devices with no data security(backed up)
-- ssd+controller with low TDW for system partitions: better off with ext4
#nilfs/nilfs2
- cow/log
- compared to f2fs - checksums data as well
- multiple checkpoints
- does not track or check write errors in existing data
- can detect inconsistency in data at checkpoint and attempt to recover (but no fsck!*)
- single stream, that packs random writes into serial
- only sequential flash writes, good for controllerless flash but reduces write speed on ssd+controller
- nearly no trim, even lower than f2fs
* https://www.spinics.net/lists/linux-nilfs/msg01938.html
-- for controller-less flash media: as storage fs (do backups)
-- all other: better avoid
#btrfs
- cow/log
- the only true self-healing fs with good fsck, that can guarantee data safety
- lots of checksumming, incl data: slower write speed, much more write cycles
- has a problem with constant tree fragmentation/reallocation: never integrate small files into tree (reiser4 fixes this, but supports no data mirroring/not inkernel)
- up to 5x more write overhead (amplification) due to consistency checks (never autotrim! use cron)
- fragments data, will cause low-level (controller level) fragmentation on overfilled ssd due to lots of random writes: never run overfilled, wipe+blkdiscard+reinstall to restore speed
- integrated duplication (mirrors) of metadata AND data, should always be ON
- deactivating data DUP(hdd/ssd+controller): ext4/xfs/f2fs become better option
- deactivating metadata DUP or noCow: zero corruption resistance
-- for storage partitions on hdd: good
-- for system/storage partitions on ssd+controller: if device has decent TBW, doesn't run overfilled
-- for system partition on ssds+controller with low TBW: use ext4 or f2fs and pray
-- for system partition on hdd: use ext4 or btrfs - and expect slow speed, but more data security.
1 Like
NFS anyone? ![]()
Welcome @DC_Boy
Setting btrfsmaintenance on Dalto’s package, I am less concerned with fragmentation. Self-healing and COW with bootable snapshots.
If you have to choose one for this distro on an average desktop or laptop, which one?
1 Like
Hmm, as per my “research”, it depends on device. This is no easy answer(*).
If he has nvme with high TBW, and he has time to setup and monitor excessive writes (moving $/.cache to tmpfs, dealing with browser profiles, etc) - if he is ok to trade speed and early device malfunction for data security - btrfs.
If device has low TBW, then for speed and device life, but very possible corruption on unclean forced shutdown and some probable chance of internal corruption of already written data - its f2fs. In worst case, its full wipe and reinstall of system partition. F2fs wasnt designed to store important data, merely as place for downloadables and cached stuff from clouds, and serve it fast with minimum wear.
Somewhere a compromise is ext4 (not 3, but4) in ordered mode. Controller packs the random writes and somewhat removes impact of journal hammering same cells. It is resistent to shutdown corruption, but ssd have a habit to silently corrupt internally. This isnt dealt by ext4, btrfs does it - at price of wear, reduced space and headache.
So its Van Damme split really.
(*) best filesystem for ssd “would be” reiser4. Would be, if … “higher forces would not use linux kernel as playfield”. Its far more technically advanced and ambicious than all these combined - however, the reality today is that was cut from development and testing, thus its promises have not fully materialized; so it has no chance as a daily driver.
PS: Zfs should not be used with consumer ssds at all. Ofc this is still load dependent, but it will write the typical consumer ssd reserves within a dozen months.
1 Like
I have been using zfs with consumer SSDs for years. I have not even gotten close to the amount of writes it would take to be concerning.
1 Like